参考自:
Probabilistic Diffusion Model概率扩散模型理论与完整PyTorch代码详细解读
diffusion 简单demo
扩散模型之DDPM
Diffusion model 原理剖析
张振虎-扩散概率模型
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
核心公式和逻辑

核心公式:

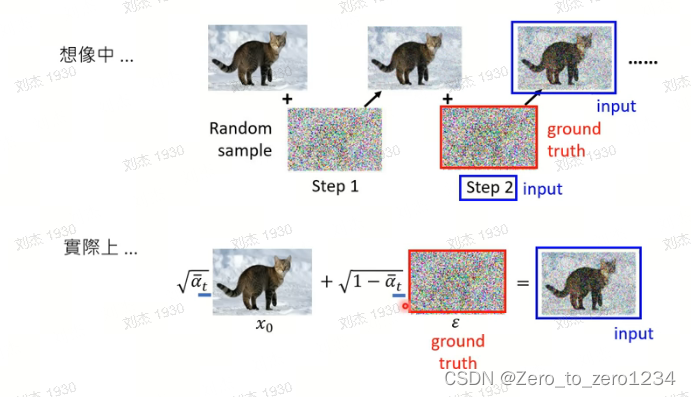
训练阶段

实际上是根据加噪后的图 和时间步 t 去预测噪声
q_x 计算公式,后面会用到:

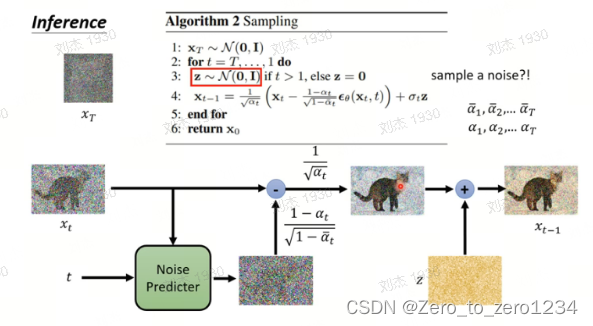
推理
代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_s_curve, make_swiss_roll
from PIL import Image
import torch
import io
# get data
# s_curve, _ = make_s_curve(10**4 , noise=0.1)
# s_curve = s_curve[:, [0, 2]] / 10.0
swiss_roll, _ = make_swiss_roll(10**4,noise=0.1)
s_curve = swiss_roll[:, [0, 2]]/10.0
print('shape of moons: ', np.shape(s_curve))
data = s_curve.T
fix, ax = plt.subplots()
ax.scatter(*data, color='red', edgecolors='white', alpha=0.5)
ax.axis('off')
# plt.show()
plt.savefig('./s_curve.png')
dataset = torch.Tensor(s_curve).float()
# set params
num_steps = 100
betas = torch.linspace(-6, 6, num_steps) # # 逐渐递增
betas = torch.sigmoid(betas) * (0.5e-2 - 1e-5) + 1e-5 # β0,β1,...,βt
print('beta: ', betas)
alphas = 1 - betas
alphas_pro = torch.cumprod(alphas, 0) # αt^ = αt的累乘
# αt^往右平移一位, 原第t步的值维第t-1步的值, 第0步补1
alphas_pro_p = torch.cat([torch.tensor([1]).float(), alphas_pro[:-1]], 0) # p表示previous, 即 αt-1^
alphas_bar_sqrt = torch.sqrt(alphas_pro) # αt^ 开根号
one_minus_alphas_bar_log = torch.log(1 - alphas_pro) # log (1 - αt^)
one_minus_alphas_bar_sqrt = torch.sqrt(1 - alphas_pro) # 根号下(1-αt^)
assert alphas.shape == alphas_pro.shape == alphas_pro_p.shape == alphas_bar_sqrt.shape == one_minus_alphas_bar_log.shape == one_minus_alphas_bar_sqrt.shape
print('beta: shape ', betas.shape)
# diffusion process
def q_x(x_0, t):
''' get q_x_{\t}
作用: 可以基于x[0]得到任意时刻t的x[t]
输入: x_0:初始干净图像; t:采样步
输出: x_t:第t步时的x_0的样子
'''
noise = torch.randn_like(x_0) # 正态分布的随机噪声
alphas_t = alphas_bar_sqrt[t]
alphas_l_m_t = one_minus_alphas_bar_sqrt[t]
return (alphas_t * x_0 + alphas_l_m_t * noise)
# test add noise
num_shows = 20
fig, axs = plt.subplots(2, 10, figsize=(28, 3))
plt.rc('text', color='blue')
# 测试一下加噪下过
## 共有10000个点,每个点包含两个坐标
## 生成100步以内,每个5步加噪后图像
for i in range(num_shows):
j = i // 10
k = i % 10
q_i = q_x(dataset, torch.tensor(i * num_steps // num_shows)) # 生成t时刻的采样数据
axs[j, k].scatter(q_i[:, 0], q_i[:, 1], color='red', edgecolor='white')
axs[j, k].set_axis_off()
axs[j, k].set_title('$q(\mathbf{x}_{' + str(i*num_steps // num_shows) + '})$')
# plt.show()
plt.savefig('diffusion_process.png')
# diffusion reverse process
# --------------------- diffusion model -----------------
import torch
import torch.nn as nn
class MLPDiffusion(nn.Module):
def __init__(self, n_steps, num_units=32):
super(MLPDiffusion, self).__init__()
self.linears = nn.ModuleList(
[
nn.Linear(2, num_units),
nn.ReLU(),
nn.Linear(num_units, num_units),
nn.ReLU(),
nn.Linear(num_units, num_units),
nn.ReLU(),
nn.Linear(num_units, 2)
]
)
self.step_embeddings = nn.ModuleList(
[nn.Embedding(n_steps, num_units),
nn.Embedding(n_steps, num_units),
nn.Embedding(n_steps, num_units),
]
)
def forward(self, x, t):
"""
模型的输入是加噪后的图片x和加噪step-> t, 输出是噪声
"""
for idx, embedding_layer in enumerate(self.step_embeddings):
t_embedding = embedding_layer(t)
x = self.linears[2 * idx](x)
x += t_embedding
x = self.linears[2 * idx + 1](x)
x = self.linears[-1](x) # shape: [10000, 2]
return x
# loss function
def diffusion_loss_fn(model, x_0, alphas_bar_sqrt, one_minus_alphas_bar_sqrt, n_steps, use_cuda=False):
"""
作用: 对任意时刻t进行采样计算loss
参数:
model: 模型
x_0: 干净的图
alphas_bar_sqrt: 根号下αt^
one_minus_alphas_bar_sqrt: 根号下(1-αt^)
n_steps: 采样步
"""
batch_size = x_0.shape[0]
# 对一个batchsize样本生成随机的时刻t, 覆盖到更多不同的t
t = torch.randint(0, n_steps, size=(batch_size//2,)) # 在0~99内生成整数采样步
t = torch.cat([t, n_steps-1-t], dim=0) # 一个batch的采样步, 尽量让生成的t不重复
t = t.unsqueeze(-1) # 扩展维度 -> [batchsize, 1]
if use_cuda:
t = t.cuda()
# x0的系数
a = alphas_bar_sqrt[t] # 根号下αt^
# eps的系数
aml = one_minus_alphas_bar_sqrt[t] # 根号下(1-αt^)
# 生成随机噪音eps
e = torch.randn_like(x_0)
if use_cuda:
e = e.cuda()
# 构造模型的输入
x = x_0 * a + e * aml # 前向过程:根号下αt^ * x0 + 根号下(1-αt^) * eps
# 送入模型,得到t时刻的随机噪声预测值
output = model(x, t.squeeze(-1)) # 模型预测的是噪声, 噪声维度与x0一样大, [10000,2]
# 与真实噪声一起计算误差,求平均值
return (e - output).square().mean()
# --------------- reverse process ---------------
def p_sample_loop(model, shape, n_steps, betas, one_minus_alphas_bar_sqrt, use_cuda=False):
"""
作用: 从x[T]恢复x[T-1]、x[T-2]、...x[0]
输入:
model:模型
shape:数据大小,用于生成随机噪声
n_steps:逆扩散总步长
betas: βt
one_minus_alphas_bar_sqrt: 根号下(1-αt^)
输出:
x_seq: 一个序列的x, 即 x[T]、x[T-1]、x[T-2]、...x[0]
"""
if use_cuda:
cur_x = torch.randn(shape).cuda()
else:
cur_x = torch.randn(shape) # 随机噪声, 对应xt
x_seq = [cur_x]
for i in reversed(range(n_steps)):
cur_x = p_sample(model, cur_x, i, betas, one_minus_alphas_bar_sqrt, use_cuda=use_cuda)
x_seq.append(cur_x)
return x_seq
def p_sample(model, x, t, betas, one_minus_alphas_bar_sqrt, use_cuda=False):
"""
作用: 从x[T]采样t时刻的重构值
输入:
model:模型
x: 采样的随机噪声x[T]
t: 采样步
betas: βt
one_minus_alphas_bar_sqrt: 根号下(1-αt^)
输出:
sample: 样本
"""
if use_cuda:
t = torch.tensor([t]).cuda()
else:
t = torch.tensor([t])
coeff = betas[t] / one_minus_alphas_bar_sqrt[t] # 模型输出的系数:βt/根号下(1-αt^) = 1-αt/根号下(1-αt^)
eps_theta = model(x, t) # 模型的输出: εθ(xt, t)
# (1/根号下αt) * (xt - (1-αt/根号下(1-αt^))*εθ(xt, t))
mean = (1/(1-betas[t]).sqrt())*(x-(coeff*eps_theta))
if use_cuda:
z = torch.randn_like(x).cuda() # 对应公式中的 z
else:
z = torch.randn_like(x) # 对应公式中的 z
sigma_t = betas[t].sqrt() # 对应公式中的 σt
sample = mean + sigma_t * z
return (sample)
# ----------- trainning ------------
print('Training model...')
if_use_cuda = True
batch_size = 1024
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4, prefetch_factor=2)
num_epoch = 4000
plt.rc('text',color='blue')
model = MLPDiffusion(num_steps) # 输出维度是2,输入是x和step
if if_use_cuda:
model = model.cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=2e-3)
iteration = 0
for t in range(num_epoch):
for idx, batch_x in enumerate(dataloader):
# 损失计算
if if_use_cuda:
loss = diffusion_loss_fn(model, batch_x.cuda(), alphas_bar_sqrt.cuda(), one_minus_alphas_bar_sqrt.cuda(), num_steps, use_cuda=if_use_cuda)
else:
loss = diffusion_loss_fn(model, batch_x, alphas_bar_sqrt, one_minus_alphas_bar_sqrt, num_steps)
optimizer.zero_grad() # 梯度清零
loss.backward() # 损失回传
torch.nn.utils.clip_grad_norm_(model.parameters(),1.) # 梯度裁剪
optimizer.step()
iteration += 1
# if iteration % 100 == 0:
if(t % 100 == 0):
print(f'epoch: {t} , loss: ', loss.item())
if if_use_cuda:
x_seq = p_sample_loop(model, dataset.shape, num_steps, betas.cuda(), one_minus_alphas_bar_sqrt.cuda(), use_cuda=True)
else:
x_seq = p_sample_loop(model, dataset.shape, num_steps, betas, one_minus_alphas_bar_sqrt, if_use_cuda)
fig, axs = plt.subplots(1, 10, figsize=(28,3))
for i in range(1, 11):
cur_x = x_seq[i*10].cpu().detach()
axs[i-1].scatter(cur_x[:,0],cur_x[:,1],color='red',edgecolor='white');
axs[i-1].set_axis_off();
axs[i-1].set_title('$q(\mathbf{x}_{'+str(i*10)+'})$')
plt.savefig('./diffusion_train_tmp.png')
### ----------------动画演示扩散过程和逆扩散过程-------------------------
# 前向过程
imgs = []
for i in range(100):
plt.clf()
q_i = q_x(dataset,torch.tensor([i]))
plt.scatter(q_i[:,0],q_i[:,1],color='red',edgecolor='white',s=5);
plt.axis('off');
img_buf = io.BytesIO()
plt.savefig(img_buf,format='png')
img = Image.open(img_buf)
imgs.append(img)
# 逆向过程
reverse = []
for i in range(100):
plt.clf()
cur_x = x_seq[i].cpu().detach()
plt.scatter(cur_x[:,0],cur_x[:,1],color='red',edgecolor='white',s=5);
plt.axis('off')
img_buf = io.BytesIO()
plt.savefig(img_buf,format='png')
img = Image.open(img_buf)
reverse.append(img)
print('save gif...')
imgs = imgs
imgs[0].save("diffusion_forward.gif", format='GIF', append_images=imgs, save_all=True, duration=100, loop=0)
imgs = reverse
imgs[0].save("diffusion_denoise.gif", format='GIF', append_images=imgs, save_all=True, duration=100, loop=0)